

In this faculty perspective, Karl Kuhnert, PhD, professor in the practice of organization and management, explores why fluency and speed in AI systems should not be mistaken for understanding — and when human judgment must remain in the loop.
“The meaning of a word is not a fixed object.” — Ludwig Wittgenstein
Why don’t people say what they really mean? How many times have you asked yourself that question? Probably more than you’d like to admit. But here’s the truth: this isn’t a flaw in how we communicate—it’s a feature. In most conversations, the real meaning lies not only in what is said, but in its source. And meaning-making is not neutral—it’s deeply personal.
Two people can hear the exact words and walk away with radically different interpretations, shaped by their own perspectives, emotional needs, and lived experiences. We are not passive recipients of information. We are interpreters—constantly filtering what we hear through cognitive and emotional frameworks.

A moment from my coaching practice illustrates this well. I once asked an executive, “What’s most important to you in leading others?” Without hesitation, he replied, “Team play.” I nodded, thinking I understood. But when I asked him to define it, he said, “Team play is the best way I can get my way.” It’s humorous in hindsight—but in the moment, it was a revealing reminder: shared language does not mean shared understanding. It rarely does.
That’s why effective leadership is less about articulation and more about interpretation. Leaders who pause to ask, “What will my words mean to them?” or “What am I not saying that people should hear?” or “How will they make sense of what they are hearing?” are the ones who truly connect, inspire, and adapt. What makes leadership powerful is not merely what is said, but how meaning is shaped between people.
Shared language does not mean shared understanding. It rarely does.
This principle becomes even more urgent as we integrate artificial intelligence (AI) into decision-making systems—especially large language models (LLMs). In our work creating decision-making digital twins for clinical and ethical decision-making, we’re learning that expertise is not simply about access to data, but about integrating explicit knowledge (facts, protocols) with tacit knowledge—the felt sense, intuition, and contextual sensitivity that human experts draw upon.
While LLMs are extraordinary at parsing and synthesizing vast amounts of text-based data, they are not designed to replicate human meaning-making. They produce answers that can appear expert but emerge from fundamentally different processes. LLMs generate plausible patterns. Humans generate meaning. One optimizes for coherence; the other searches for truth. This contrast is illustrated in the accompanying diagram comparing human judgment and large language models.
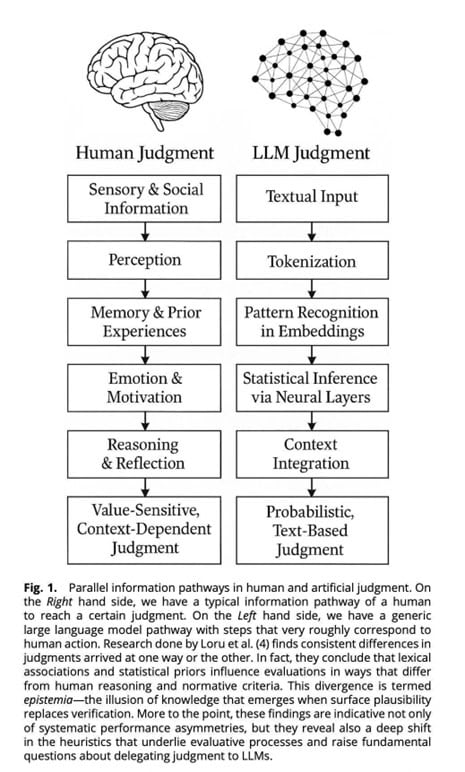
Figure 1
Parallel Pathways of Judgment in Humans and LLMs
Note. Adapted from Loru et al. (2025). This diagram compares the information-processing pathways in humans (left) and large language models (right). While both arrive at judgments, they do so via fundamentally different mechanisms: human reasoning integrates sensory, emotional, and motivational input—producing context-dependent, value-sensitive reflection. LLMs operate on tokenized text and use statistical inference to produce outputs based on probabilistic associations.
Recent work by Quattrociocci and his team (Loru et al., 2025) has reinforced this insight: while LLMs can often mirror expert outputs, they lack the human capacity for judgment, shaped by values, ambiguity, and ethical nuance. The researchers term this divergence epistemia—the illusion of understanding produced when probabilistic output mimics deeper forms of reflection—when persuasive semantics poses as knowledge. The danger of epistemia is not just technological. It’s personal. LLMs detect patterns and probabilities. Humans discern purpose and meaning. One mimics understanding; the other embodies it.
LLMs generate plausible patterns. Humans generate meaning.
In contexts where tacit knowledge matters most—healthcare, leadership, ethics, crisis response- accepting AI judgments as human discernment risks replacing wisdom with synthesized coherence.
What we need is not to ask whether LLMs can render expert judgments, but how those judgments are made. Fluency is not understanding. Speed is not wisdom. Certainty is not truth. In a world increasingly optimized for answers, it is the questions we live with, and the wisdom we bring to them, that will matter most. We do need to ask now when it matters most that human judgment is in the loop.
From exploring how meaning and judgment shape leadership to examining the role of AI in ethical decision-making, Goizueta faculty combine academic rigor with real-world relevance. Explore more faculty insights and innovations.
Reference:
Loru, E., Nudo, J., Stirrup, A., Abu-Mostafa, R., Caldarelli, M., Cingolani, V., Rodriguez-Arias, C., & Quattrociocchi, W. (2025). The simulation of judgment in LLMs. Proceedings of the National Academy of Sciences, 122(42), e2518443122. doi.org








